
1、订单号命名规则
- 不重复:必须全局唯一。
- 安全性:订单号需要做到不容易被人为的猜测或者推测出来,例如订单号就是流水号的话,那么别人就很容易从订单号推测出公司的整体运营情况。
- 禁用随机码:很多人分析生成订单号的时候,第一个念头肯定是不重复唯一性,那么第二个念头可能就是安全性,想要同时满足前两者,很容易想到使用随机码,随机码从一定程度来说,更安全、不重复性更高,但是可读性差,有概率会发生重复。
- 防止并发:针对系统的并发业务场景(如秒杀),需要做到并发场景下,订单编号生成快速、不重复等要求
- 控制位数:订单号的位数尽量在 10 位 ~ 18 位之间。太短的情况下,如果交易量过大,很难做到防止重复,太长可读性差、意义也不大。
2、常见实践方案
2.1 UUID
UUID 是Universally Unique Indentifier的缩写,翻译为通用唯一识别码,顾名思义 UUID 是一个用于记录唯一标识一条的数据,其按照开放软件基金会(OSF)指定的标准进行计算,用到了以太网卡地址(MAC)、纳秒级时间、芯片 ID 码和许多可能的数字。
总的来说,UUID 码由以下三部分组成:
-
当前日期和时间
-
时钟序列
-
全局唯一的 IEEE 机器识别码(如果有网卡从网卡获得,没有网卡则通过其他方式获得)
UUID 的标准形式包含 32 个 16 进制数字,以连字号分为五段,示例:
00000191-adc6-4314-8799-5c3d737aa7de36位这种方案,虽然实现简单、方便;但是内容长,在实际的项目场景开发中,一般用于于记录用户的手机设备ID等硬件信息
2.2 数据库自增
所谓数据库自增,意思是在数据库中给某个列设置为自增列,并且给该列设置一个初始值,代码层面无需任何特殊处理。
这种通过数据库自增方式实现唯一值,在单体服务下是没有问题,但是在大流量分布式服务环境下,并发性能很低。
以后数量大的时候,需要对 mysql 进行分库分表,此时订单号会重复。
2.3 雪花算法
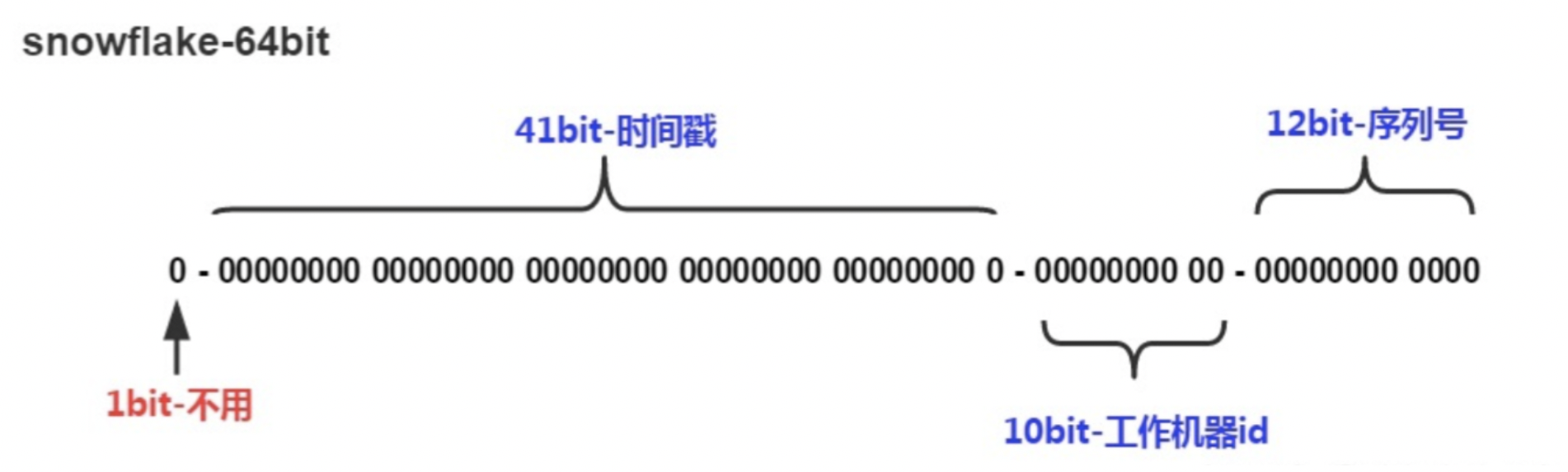
Snowflake 由 4个部分组成:
-
第一部分:bit 值,为未使用的符号位
-
第二部分:由 41 位的时间戳(毫秒)构成,它的取值是当前时间相对于某一时间的偏移。 (2^41 -1毫秒)/(1000606024365) =69年
这里减去1的原因就是因为数值范围是从0开始计算的,而不是从1开始的。
-
第三部分:表示工作机器 id,由服务节点 id 和数据中心 id 组合而成
-
第四部分:表示每个工作机器每毫秒生成的序列号 ID,同一毫秒内最多可生成生产 4095 个 ID。
SnowFlake 算法可以保证:
-
能满足高并发分布式系统环境下ID不重复
-
生成效率高
-
基于时间戳,可以保证基本有序递增
-
不依赖于第三方的库或者中间件
-
生成的
id具有时序性和唯一性
在高并发的环境下,Snowflake 算法可以生成全局唯一的订单编号,长度为19位。
go的雪花算法实现:https://blog.miuyun.work/archives/11742373
2.4 分布式组件
要想在分布式环境下生成一个唯一的订单编号,我们可以通过分布式组件的方式,来帮忙我们生成全局唯一的订单号,例如我们可以采用 redis 分布式缓存组件中的incr命令,来帮我们生成一个全局自增长的序列号。
例子:小米订单号
1211218032345170(16位)
可以将其分解成四个部分
1——211218—03234—5170
- 第一部分,1 表示购买,2 表示退货。
- 第二部分,表示 2021 年 12 月 18 日下的单,前面两位省掉了。
- 第三部分,时间戳对应
00:53:54,换算成秒是03234秒。 - 最后一部分,表示在同一秒内下的第 5170 单,也就是说,小米认为,在一秒内不会超过一万个订单。
3、方案优缺点对比
| 实践方案 | 优点 | 缺点 |
|---|---|---|
| UUID | 实现简单、方便、重复性低 | 数据库查询效率相对低;毫无规律 |
| 数据库自增 | 利用mysql特点实现数据递增;代码层面无需任何处理 | 并发性能差,分库分表情况下,会发生重复; |
| 雪花算法 | 基于内存、速度快、性能高;不会产生额外的网络开销;数据依次递增;支持分布式环境。 | 依赖于服务器时间,如变动服务器时间则存在重复情况; |
| 分布式组件 | 基于内存、速度快;使用简单;可分布数据、扩展性强 | 需要独立搭建一套服务、增加了维护成本;跨应用调用,存在网络开销 |
4、业界案例
4.1 淘宝
订单编号:纯数字19位。 交易号:时间年月日(8位)+ 数字(20位)= 28位
