
1、简介
etcd是一个非常可靠的kv存储系统,常在分布式系统中存储着关键的数据。内部采用raft一致性算法,基于go实现。
特点:
- 简单:提供定义明确且面向用户的API(HTTP+JSON, gRPC)
- 安全:支持SSL证书验证
- 性能:基准压测支持1w+/sec写入
- 可靠:采用Raft协议保证分布式系统数据的可用性和一致性。
2、常见功能
- 键值存储、查询功能:支持精准查询、range操作、ttl机制、key版本等。
- 一致性机制:采用raft协议保证强一致性。主节点处理所有来自客户端写操作,通过Raft协议保证写操作对状态机的改动会可靠的同步到其他节点。
- 可用性机制:提供集群和leader选举机制。
- SSL认证机制。
- watch机制,提供持续监听某个key变化的功能,以及基于TTL的key的自动过期机制。
- 支持CAS(compare and swap)操作
- 支持多key的事务操作
- 支持目录操作
3、应用场景
3.1 配置中心
etcd是一个分布式的键值存储系统,其优秀的读写性能、一致性和可用性的机制,非常适合用来做配置中心角色。
3.2 分布式锁
etcd的强一致性保证,可以用来做分布式场景下的同步机制保证。锁服务有两种使用方式,一是保持独占,二是控制时序。
- 保持独占即所有获取锁的用户最终只有一个可以得到。etcd 为此提供了一套实现分布式锁原子操作 CAS(
CompareAndSwap)的 API。通过设置prevExist值,可以保证在多个节点同时去创建某个目录时,只有一个成功。而创建成功的用户就可以认为是获得了锁。 - 控制时序,即所有想要获得锁的用户都会被安排执行,但是获得锁的顺序也是全局唯一的,同时决定了执行顺序。etcd 为此也提供了一套 API(自动创建有序键),对一个目录建值时指定为
POST动作,这样 etcd 会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用 API 按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
3.3 leader选举组件
分布式场景下,常采用leader-follower模式来保证有状态服务的高可用(即使leader挂掉,其他follower立马补上),比如k8s和kafka partition高可用机制。可以很方便的借助etcd来实现leader选举机制。
3.4 服务注册与服务发现
为了解决微服务场景下,服务地址的注册和发现问题。和配置中心功能类似,不同之处在于服务注册和服务发现,还伴随着状态检测。
服务发现就是要了解集群中是否有进程在监听upd或者tcp端口,并且通过名字就可以进行查找和连接。用户可以在 etcd 中注册服务,并且对注册的服务设置key TTL,定时保持服务的心跳以达到监控健康状态的效果。通过在 etcd 指定的主题下注册的服务也能在对应的主题下查找到。
3.5 消息订阅和发布
etcd内置watch机制,完全可以实现一个小型的消息订阅和发布组件。
在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。通过这种方式可以做到分布式系统配置的集中式管理与动态更新。
3.6 负载均衡
分布式系统中,为了保证服务的高可用以及数据的一致性,通常都会把数据和服务部署多份,以此达到对等服务,即使其中的某一个服务失效了,也不影响使用。由此带来的坏处是数据写入性能下降,而好处则是数据访问时的负载均衡。因为每个对等服务节点上都存有完整的数据,所以用户的访问流量就可以分流到不同的机器上。
4、和同类产品的对比
4.1 etcd vs redis
etcd诞生之日起,就定位成一种分布式存储系统,并在k8s 服务注册和服务发现中,为大家所认识。它偏重的是节点之间的通信和一致性的机制保证,并不强调单节点的读写性能。
而redis最早作为缓存系统出现在大众视野,也注定了redis需要更加侧重于读写性能和支持更多的存储模式,它不需要care一致性,也不需要侧重事务,因此可以达到很高的读写性能。
4.2 etcd vs consul
consul定位是一个端到端的服务框架,提供了内置的监控检查、DNS服务等,除此之外,还提供了HTTP API和Web UI,如果要实现简单的服务发现,基本上可以开箱即用。
但是缺点同样也存在,封装有利有弊,就导致灵活性弱了不少。
4.3 etcd vs zookeeper
- 一致性协议: etcd使用[Raft]协议, zk使用ZAB(类PAXOS协议),前者容易理解,方便工程实现;
- 运维方面:etcd方便运维,zk难以运维;
- 项目活跃度:etcd社区与开发活跃,zk已经快死了;
- etcd提供HTTP+JSON, gRPC接口,跨平台跨语言,zk使用其客户端;
- 访问安全方面:etcd支持HTTPS访问,zk在这方面缺失;
5、架构
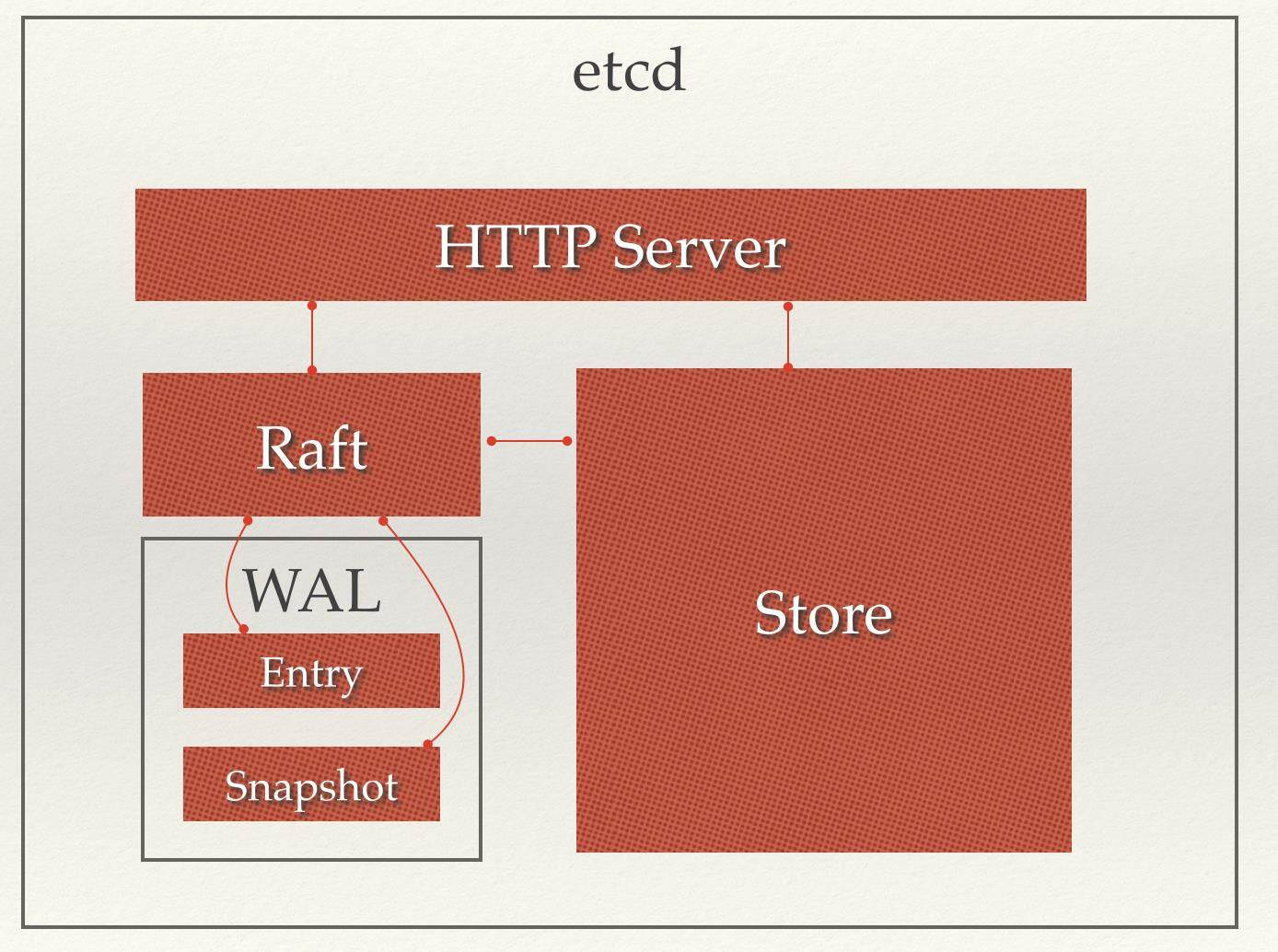
从 etcd 的架构图中我们可以看到,etcd 主要分为四个部分。
-
HTTP Server: 用于处理用户发送的 API 请求以及其它 etcd 节点的同步与心跳信息请求。
-
Store:用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是 etcd 对用户提供的大多数 API 功能的具体实现。
-
Raft:Raft 强一致性算法的具体实现,是 etcd 的核心。
-
WAL:Write Ahead Log(预写式日志),是 etcd 的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd 就通过 WAL 进行持久化存储。WAL 中,所有的数据提交前都会事先记录日志。Snapshot 是为了防止数据过多而进行的状态快照;Entry 表示存储的具体日志内容。
通常,一个用户的请求发送过来,会经由 HTTP Server 转发给 Store 进行具体的事务处理,如果涉及到节点的修改,则交给 Raft 模块进行状态的变更、日志的记录,然后再同步给别的 etcd 节点以确认数据提交,最后进行数据的提交,再次同步。
6、数据存储
etcd 的存储分为内存存储和持久化(硬盘)存储两部分,内存中的存储除了顺序化的记录下所有用户对节点数据变更的记录外,还会对用户数据进行索引、建堆等方便查询的操作。
持久化则使用预写式日志(WAL:Write Ahead Log)进行记录存储。在 WAL 的体系中,所有的数据在提交之前都会进行日志记录。在 etcd 的持久化存储目录中,有两个子目录。一个是 WAL,存储着所有事务的变化记录;另一个则是 snapshot,用于存储某一个时刻 etcd 所有目录的数据。通过 WAL 和 snapshot 相结合的方式,etcd 可以有效的进行数据存储和节点故障恢复等操作。
6.1 预写式日志(WAL)
WAL(Write Ahead Log)最大的作用是记录了整个数据变化的全部历程。在 etcd 中,所有数据的修改在提交前,都要先写入到 WAL 中。使用 WAL 进行数据的存储使得 etcd 拥有两个重要功能。
- 故障快速恢复: 当你的数据遭到破坏时,就可以通过执行所有 WAL 中记录的修改操作,快速从最原始的数据恢复到数据损坏前的状态。
- 数据回滚(undo)/ 重做(redo):因为所有的修改操作都被记录在 WAL 中,需要回滚或重做,只需要方向或正向执行日志中的操作即可。
7、节点变更
7.1 节点迁移、替换
当你节点所在的机器出现硬件故障,或者节点出现如数据目录损坏等问题,导致节点永久性的不可恢复时,就需要对节点进行迁移或者替换。当一个节点失效以后,必须尽快修复,因为 etcd 集群正常运行的必要条件是集群中多数节点都正常工作。
迁移一个节点需要进行四步操作:
- 暂停正在运行着的节点程序进程
- 把数据目录从现有机器拷贝到新机器
- 使用 api 更新 etcd 中对应节点指向机器的 url 记录更新为新机器的 ip
- 使用同样的配置项和数据目录,在新的机器上启动 etcd。
7.2 节点增加
增加节点可以让 etcd 的高可用性更强,同时,增加节点还可以让 etcd 集群具有更好的读性能。因为 etcd 的节点都是实时同步的,每个节点上都存储了所有的信息,所以增加节点可以从整体上提升读的吞吐量。
增加一个节点需要进行两步操作:
- 在集群中添加这个节点的 url 记录,同时获得集群的信息。
- 使用获得的集群信息启动新 etcd 节点。
7.3 节点移除
Leader 节点在提交一个写记录时,会把这个消息同步到每个节点上,当得到多数节点的同意反馈后,才会真正写入数据。所以节点越多,写入性能越差。在节点过多时,你可能需要移除一个或多个。
移除节点只需要集群中这个节点的记录删除,然后对应机器上的该节点就会自动停止。
7.4 强制性重启集群
当集群超过半数的节点都失效时,就需要通过手动的方式,强制性让某个节点以自己为 Leader,利用原有数据启动一个新集群。
etcd 目前没有任何机制会自动去变化整个集群总共的节点数量,即如果没有人为的调用 API,etcd 宕机后的节点仍然被计算为总节点数中,任何请求被确认需要获得的投票数都是这个总数的半数以上。
重启集群需要进行两步操作:
- 备份原有数据到新机器。
- 使用
-force-new-cluster加备份的数据重新启动节点
强制性重启是一个迫不得已的选择,它会破坏一致性协议保证的安全性(如果操作时集群中尚有其它节点在正常工作,就会出错)
参考链接:
https://zhuanlan.zhihu.com/p/339902098
https://developer.aliyun.com/article/11035
https://www.infoq.cn/article/etcd-interpretation-application-scenario-implement-principle/
如有不对,烦请指出,感谢!