
因为个人用的go,所以调研及对比主要针对适配了go语言的数据库。
一、当前主流的时序数据库
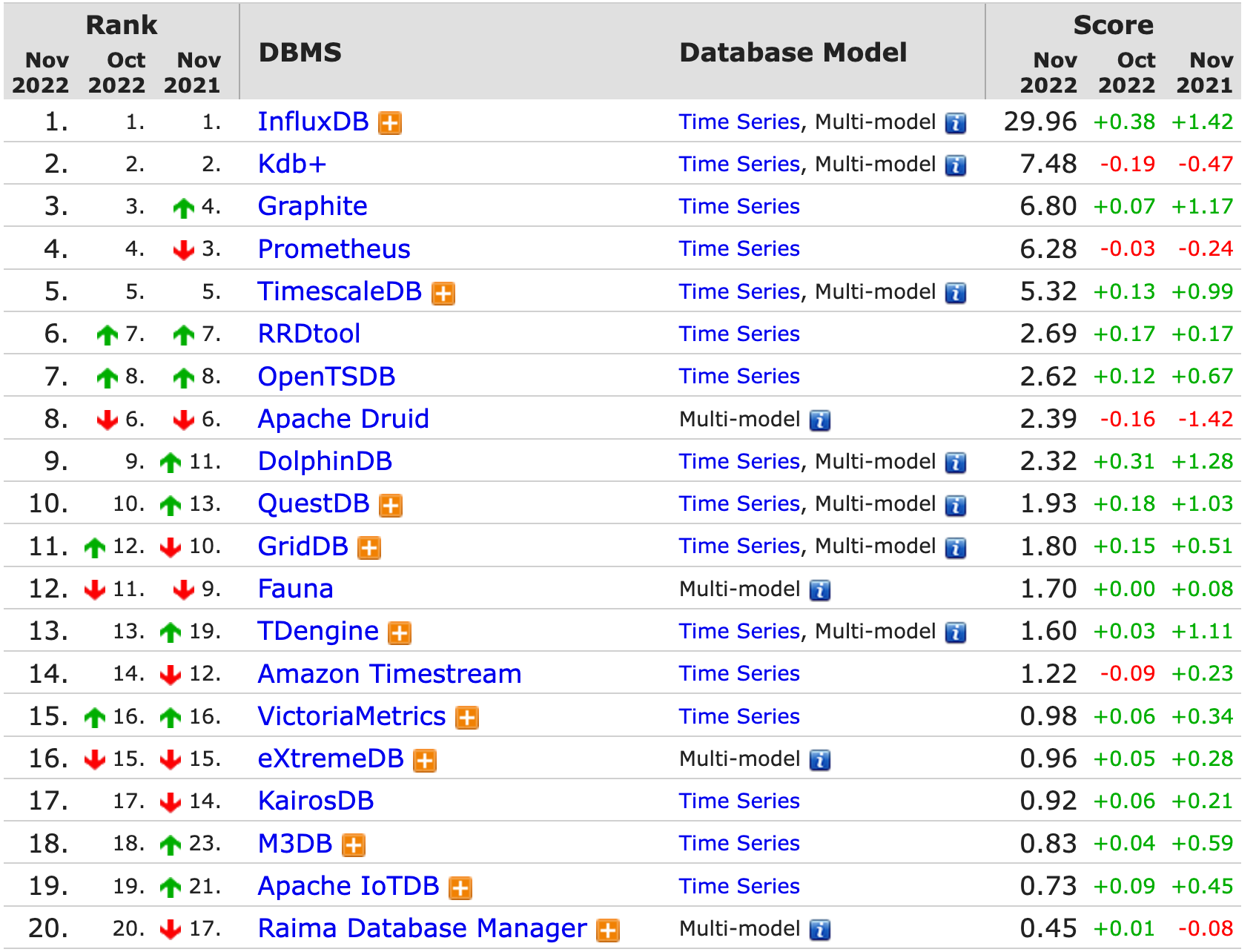
二、主流时序数据库分析
1、Influxdb
流行度很高,支持Go语言,社区活跃度高
特性:
- 高效的时间序列数据写入性能。自定义TSM引擎,快速数据写入和高效数据压缩;
- 无额外存储依赖;
- 简单,高性能的HTTP查询和写入API;
- 以插件方式支持许多不同协议的数据摄入,如:graphite,collectd,和openTSDB;
- SQL-like查询语言,简化查询和聚合操作;
- 索引Tags,支持快速有效的查询时间序列;
- 保留策略有效去除过期数据;
- 连续查询自动计算聚合数据,使频繁查询更有效。
缺点:
- 分布式未开源。
2、Timescale
一个基于传统关系型数据库postgresql改造的时间序列数据库。
优点:
-
PostgreSQL原生支持的所有SQL,包含完整SQL接口(包括辅助索引,非时间聚合,子查询,JOIN,窗口函数);
-
用PostgreSQL的客户端或工具,可以直接应用到该数据库,不需要更改;
-
时间为导向的特性,API功能和相应的优化;
-
透明时间/空间分区,用于放大(单个节点)和扩展;
-
高数据写入速率(包括批量提交,内存中索引,事务支持,数据备份支持);
-
单个节点上的大小合适的块(二维数据分区),以确保即使在大数据量时即可快速读取;
-
块之间和服务器之间的并行操作。
劣势:
- 因为TimescaleDB没有使用列存技术,它对时序数据的压缩效果不太好,压缩比最高在4X左右,长远考虑,专业的TSDB必须是从底层存储面向时序数据的特征进行针对性设计和优化的;
- 目前暂时不完全支持分布式的扩展(正在开发相关功能),所以会对服务器单机性能要求较高。
3、Apache Druid
【不支持GO】
Druid是一个实时在线分析系统(LOAP)。其架构融合了实时在线数据分析,全文检索系统和时间序列系统的特点,使其可以满足不同使用场景的数据存储需求,在极致性能和数据schema的灵活性方面有一定的平衡。
优点:
- 采用列式存储:支持高效扫描和聚合,易于压缩数据;
- 可伸缩的分布式系统:Druid自身实现可伸缩,可容错的分布式集群架构。部署简单;
- 强大的并行能力:Druid各集群节点可以并行地提供查询服务;
- 实时和批量数据摄入:Druid可以实时摄入数据,如通过Kafka。也可以批量摄入数据,如通过Hadoop导入数据;
- 自恢复,自平衡,易于运维:Druid自身架构即实现了容错和高可用。不同的服务节点可以根据响应需求添加或减少节点;
- 容错架构,保证数据不丢失:Druid数据可以保留多副本。另外可以采用HDFS作为深度存储,来保证数据不丢失;
- 索引:Druid对String列实现反向编码和Bitmap索引,所以支持高效的filter和groupby;
- 基于时间分区:Druid对原始数据基于时间做分区存储,所以Druid对基于时间的范围查询将更高效;
- 自动预聚合:Druid支持在数据摄入期就对数据进行预聚合处理。
缺点:
- 不支持多时间维度,所有维度为String类型;
- 只支持流式写入,不支持实时数据更新,更新可以使用批处理作业完成;
- 不支持精准去重。
4、Kdb+
kdb+ 号称最快的内存数据库之一。列式存储的特性,使得对于某个列的统计分析操作异常方便。
优点:
- 单体架构,轻松支持 billion以上数据;
- 分布式扩展,无性能损耗;
- 超低延迟+高并发支持;
- 列式存储+内存数据库;
- 灵活的Q语言,内置非常多的统计计算方法。
缺点:
- 搭配的Q 语言,学习难度较高。
5、Graphite
【不支持GO】
Graphite通常用于监控基础设施级别的度量,比如CPU、内存、I/O利用率、网络吞吐量和延迟,当然Graphite在应用程序级的度量和业务级的度量方面也很不错。
6、RRDtool
【不支持GO】
RRDtool 代表 “Round Robin Database tool” , 所谓的“Round Robin” 其实是一种存储数据的方式,使用固定大小的空间来存储数据,并有一个指针指向新的数据的位置。
优点:
- 使用RRD(Round Robin Database)存储格式,数据等于放在数据库中,可以方便地调用。比如,将一个RRD文件中的数据与另一个RRD文件中的数据相加;
- 可以定义任意时间段画图,可以用半年数据画一张图,也可以用半小时内的数据画一张图;
- 能画任意个DS,多种图形显示方式;
- 数据存储与绘图分开,减轻系统负载;
- 能任意处理RRD文件中的数据,比如,在浏览监测中我们需要将数据由Bytes转化为bits,可以将原始数据乘8。
缺点:
- RRDTool的作用只是存储数据和画图,它没有MRTG中集成的数据采集功能;
- 在命令行下的使用非常复杂,参数极多;
- 无用户、图像管理功能。
7、OpenTSDB
OpenTSDB 是一个开源框架,使用 HBase 作为核心平台来存储和检索所收集的指标数据,可以灵活地增加指标,也可以支持采集上万台机器和上亿个数据点,具有高可扩展性。
优点:
- 在数据压缩上,时间戳采用 delta 编码进行压缩,数据值采用 XOR 进行压缩;
- 存储与计算解耦,为 IoT 场景海量数据、动态热点的数据特征量身打造,方便按照并发度和存储量按需独立扩容。采用分布式架构,支持横向水平扩展;
- 较强的时序数据计算能力,主要体现为:插值,缺失的数据点,支持线性插值数据补全;
- 降精度,支持预降精度和实时降精度计算,满足高效查询需求;
- 空间聚合,支持按照不同的 tag 进行空间聚合和分组计算。
缺点:
- 数据查询和分析的能力不足,不是所有的查询场景都能适用,在GroupBy和Downsampling的查询上,也未提供Pre-aggregation和Auto-rollup的支持,查询效率不如其他数据库;
- 基于HBase构建,依赖Hadoop生态太重。
8、Prometheus
Prometheus 是一个开源的服务监控系统和时间序列数据库。
优点:
- 具有丰富的查询语言;
- 可视化数据展示;
- 集成监控和报警功能;
- 维护简单。
缺点:
- 没有集群解决方案;
- 聚合分析能力较弱;
- 为运行时正确的监控数据准备的,不能解决大容量存储问题,无法做到100%精准,存在由内核故障、刮擦故障等因素造成的微小误差。
9、DolphinDB
DolphinDB是一款高性能分布式时序数据库,主要是解决海量结构化数据的快速存储和计算,以及通过内存数据库和流数据实现高性能的数据处理。
优点:
- 列式混合引擎(基于内存和磁盘),支持单表百万级别的分区数,大大缩减对海量数据的检索响应时间;
- 内嵌的分布式文件系统自动管理分区数据及其副本,为分布式计算提供负载均衡和容错能力;
- 支持命令式编程、函数式编程、向量编程、SQL编程和RPC(远程函数调用)编程;
- 内置Web服务器,用于集群管理、性能监控和数据访问。
缺点:
-
DolphinDB是为OLAP的场景优化设计的,支持添加数据,不支持对个别行进行删除或更新。如果要修改数据,以分区为单位覆盖全部数据;
-
由于产品的竞品更加明确,市场更加专业化,并不开放源代码也不允许免费版本在商业场景中使用
10、IoTDB
IoTDB 是一个用于管理大量时间序列数据的数据库,它采用了列式存储、数据编码、预计算和索引技术,具有类 SQL 的接口,可支持每秒每节点写入数百万数据点,可以秒级获得超过数万亿个数据点的查询结果。主要面向工业界的IoT场景。
优点:
- 压缩比高(优于1:10无损压缩),可大大节省服务器硬件成本;
- 开箱即用,跨平台部署,仅依靠 JDK/JRE;
- 类sql查询,学习成本低。
缺点:
- 暂时不支持集群;
- TSFile(一种列存储文件格式,用于访问,压缩和存储时序数据)结构版本单一。
11、QuestDB
QuestDB
QuestDB 是一个高性能、开源的 SQL 数据库,适用于金融服务、物联网、机器学习 、DevOps 和可观测性应用。它拥有支持 PostgreSQL 线协议的端点,使用 InfluxDB 线协议的模式,无关的高吞吐数据获取方式,以及用于查询、批量导入和导出的 REST API。
优点:
- 快速摄取(特别是对于具有高基数的数据集),支持InfluxDB内联协议和PostgreSQL wire,可以通过标准的SQL查询数据;
- 提供一些列的时序扩展 SQL,让时序查询的表达更简单;
- 自带 web console 及 demo,易于上手使用。
缺点:
- 缺乏生产环境就绪的功能(如,复制、备份与恢复等;
- 虽然能与诸如:PostgreSQL、Grafana、Kafka、Telegraf、以及Tableau等流行工具相集成,但是需要花时间调试与磨合,方可达到一般TSDB的水平。
12、TDengine
TDengine
TDengine 是一款开源、高性能、分布式、支持 SQL 的时序数据库,其时序数据库核心代码包括集群功能全部开源,同时 TDengine 还带有内建的缓存、流式计算、数据订阅等系统功能,能大幅减少研发和运维的复杂度
优点:
-
支持水平扩展,有开源的分布式集群解决方案;
-
性能测试中读写性能远高于InfluxDB,压缩率高;
-
采用标准 SQL 做查询语言(不完全兼容),并且采用关系数据库模型,学习成本低;
缺点:
-
比较复杂的sql功能还不支持
-
单条插入性能很低,必须成批写入,增加了系统开发和维护的复杂度与运营成本
-
大厂实践少
13、云厂商
-
阿里云
TSDB for InfluxDB,自研的TSDB引擎,将单个数据点的平均使用存储空间降为1~2个字节,可以降低90%存储使用空间,同时加快数据写入的速度,相较于开源的 OpenTSDB 和 InfluxDB,读写效率提升了数倍,同时兼容 OpenTSDB 数据访问协议。 -
华为云
GaussDB for Influx,基于InfluxDB进行深度优化改造,在架构、性能和数据压缩等方面进行了技术创新
MRS,基于IoTDB进行优化,千万级数据点秒级写入,TB级数据毫秒级查询;优化后的数据压缩比可达百倍,进一步节省存储空间和成本。 -
腾讯云
TencentDB for CTSDB,一款分布式、可扩展、支持近实时数据搜索与分析的时序数据库,借鉴了ElasticSearch内核深度优化经验,兼容 Elasticsearch 常用的 API 接口和生态,性能方面可以做到每秒千万级数据点写入,亿级数据秒级分析。
三、选型
Go语言、存储普通的时序数据、进行一般的聚合查询
- 免费、分布式
推荐tdengine - 免费、单节点
推荐 questdb、tdengine - 付费
没测试过,无推荐
参考链接:
https://db-engines.com/en/system/DolphinDB%3BInfluxDB%3BOpenTSDB%3BTDengine
http://jianfei.blog.csdn.net/article/details/127386117
https://bbs.huaweicloud.com/blogs/300156
https://blog.csdn.net/xuruilll/article/details/125808992
如有不对,烦请指出,感谢~