
目录
一、定位慢SQL
1.首先确认是否开启了慢查询
mysql> show variables like "%slow%";
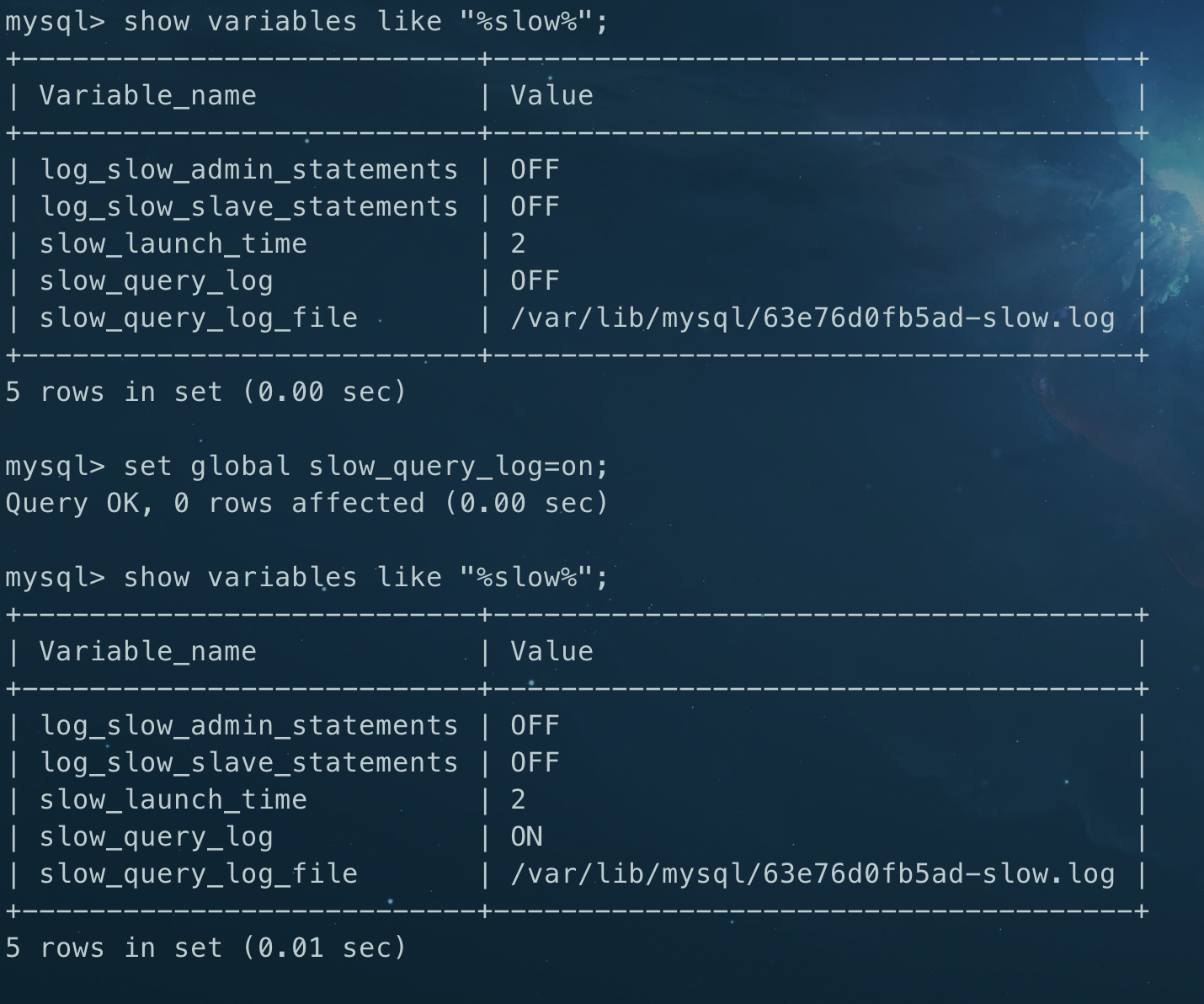
slow_query_log为OFF,表示未开启慢查询,直接set global slow_query_log=on;slow_query_log_file是存放慢查询日志的地址
(set global 只是全局session生效,重启后失效,如果需要以上配置永久生效,需要在mysql.ini(linux my.cnf)中配置)
2.设置慢查询的时间限制
mysql> show variables like "long_query_time";
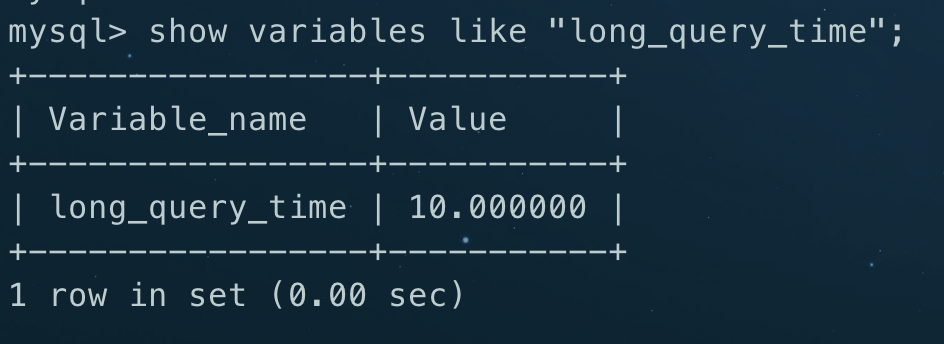
value值即为操作时长大于该值后就认为是慢sql
测试时值可以设置得小些
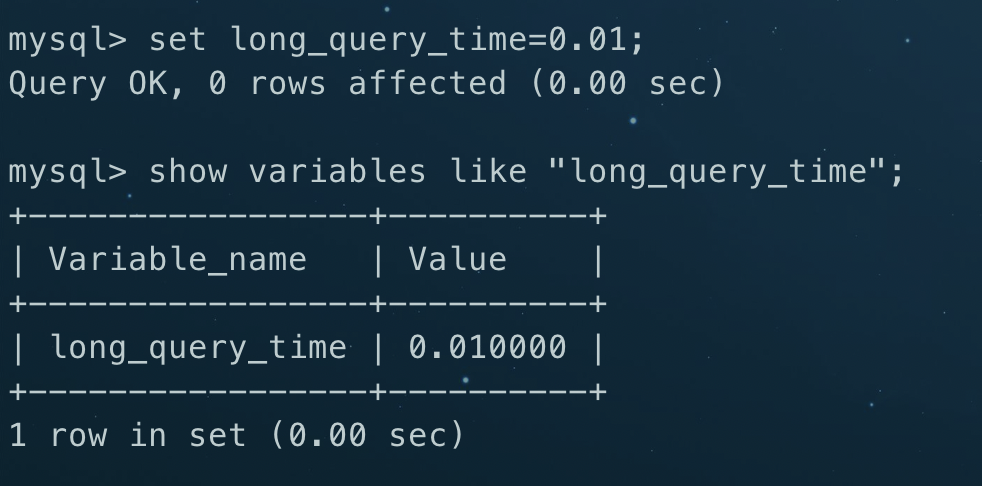
3.查询慢查询日志可定位具体的慢sql
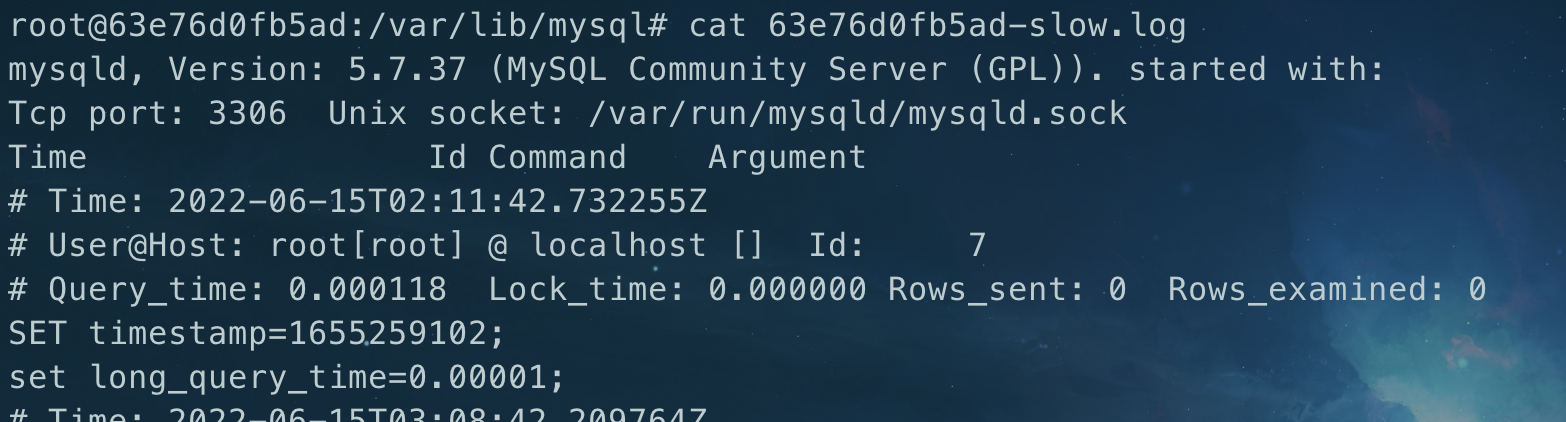
Time :日志记录的时间
User@Host:执行的用户及主机
Query_time:查询耗费时间 Lock_time 锁表时间 Rows_sent 发送给请求方的记录条数 Rows_examined 语句扫描的记录条数
SET timestamp 语句执行的时间点
执行的语句
4.相关sql查询
查询mysql的操作信息show status 显示全部mysql操作信息
/* 获得mysql的插入次数; */
show status like "com_insert%";
/* 获得mysql的删除次数; */
show status like "com_delete%";
/* 获得mysql的查询次数; */
show status like "com_select%";
/* 获得mysql服务器运行时间; */
show status like "uptime";
/* 获得mysql连接次数; */
show status like 'connections';
/* 服务器启动以来执行时间最长的20条SQL语句; */
5.用Explain分析具体的sql语句


id:选择标识符
select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型
possible_keys:表示查询时,可能使⽤的索引
key:表示实际使⽤的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的⾏百分比
Extra:执行情况的描述和说明
二、慢SQL优化
1. 不使用子查询
SELECT * FROM t1 WHERE id (SELECT id FROM t2 WHERE name='hechunyang');
(优化只针对SELECT有效,对UPDATE/DELETE子 查询无效)
2.读取适当的记录LIMIT M,N
可以改为:
SELECT * FROM t WHERE 1 LIMIT 10;
3.分组统计可以禁止排序
SELECT goods_id,count(*) FROM t GROUP BY goods_id;
默认情况下,MySQL对所有GROUP BY col1,col2…的字段进⾏排序。如果查询包括GROUP BY,想要避免排序结果的消耗,则可以指定ORDER BY NULL禁止排序。
可以改为:
SELECT goods_id,count(*) FROM t GROUP BY goods_id ORDER BY NULL;
4.禁止不必要的ORDER BY排序
SELECT count(1) FROM user u LEFT JOIN user_info i ON u.id = i.user_id WHERE 1 = 1 ORDER BY u.create_time DESC;
可以改为:
SELECT count(1) FROM user u LEFT JOIN user_info i ON u.id = i.user_id;
5.尽量不要超过三个表join
需要join的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引
6.在varchar字段上建立索引时,必须指定索引长度
没必要对全字段建立索引,根据实际文本区分度决定索引长度。
索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为20的索引,区分度会高达90%以上,可以使用count(distinct left(列名, 索引长度))/count(*)的区分度来确定
7.不要使用 select *
只返回需要的字段
8.排序请尽量使用升序
9.尽量使用数字型字段
若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
10.避免索引失效
10.1 字段类型转换导致不用索引
如字符串类型的不用引号,数字类型的用引号等,这有可能会用不到索引导致全表扫描;
10.2 根据联合索引的第二个及以后的字段单独查询用不到索引
10.3 字段前面不能加函数/加减运算,否则会导致索引失效
如下面语句将进行全表扫描:
select id from t where num/2=100
SELECT * FROM t WHERE YEAR(d) >= 2016
可以改为:
select id from t where num=100*2
SELECT * FROM t WHERE d >= '2016-01-01';
10.4 搜索严禁左模糊或者全模糊
select name from t where name like %s
select name from t where name like %s%
如果需要请走搜索引擎来解决,因为索引文件具有B-Tree的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
10.5 避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描
select id from t where num != 2
可以改为:
select id from t where num > 2 and num < 2
10.6 避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
select id from t where num is null
可以改为:设置num的默认值为0,确保没有null值
select id from t where num=0
10.7 用IN或UNION来替换OR低效查询
SELECT * FROM t WHERE LOC_ID = 10 OR LOC_ID = 20 OR LOC_ID = 30;
可以改为:
SELECT * FROM t WHERE LOC_IN IN (10,20,30);
或
SELECT * FROM t WHERE LOC_IN = 10 UNION ALL SELECT * FROM t WHERE LOC_IN = 20 UNION ALL SELECT * FROM t WHERE LOC_IN = 30
对于连续的数值,能用 between 就不要用 in 了
select id from t where num between 1 and 3
10.8 在 where 子句中使用参数,也会导致全表扫描
因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num
11.删除表所有记录请用 truncate,不要用 delete
12.存储过程和触发器设置
在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
13.使用基于游标的方法或临时表
尽量避免使用游标,因为游标的效率较差
使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
14.使用临时表
当需要重复引用大型表或常用表中的某个数据集时,可以使用临时表。但是,对于一次性事件,最好使用导出表。
在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
避免频繁创建和删除临时表,以减少系统表资源的消耗。
参考链接:
https://www.jianshu.com/p/600503b1c791
https://zhuanlan.zhihu.com/p/442169347
https://www.jianshu.com/p/3ab117c83d0b
如有不对,烦请指出,感谢~